| |||||||||||||||||||||||||||||||||||||||||||




| |||||||||||||||||||||||||||||||||||||||||||
Find Your Site's Biggest Technical Flaws in 60 Minutes |
| Find Your Site's Biggest Technical Flaws in 60 Minutes Posted: 05 Feb 2012 01:14 PM PST Posted by Dave Sottimano I've deliberately put myself in some hot water to demonstrate how I would do a technical SEO site audit in 1 hour to look for quick fixes, (and I've actually timed myself just to make it harder). For the pros out there, here's a look into a fellow SEO 's workflow; for the aspiring, here's a base set of checks you can do quickly. I've got some lovely volunteers who have kindly allowed me to audit their sites to show you what can be done in as little as 60 minutes. I'm specifically going to look for crawling, indexing and potential Panda threatening issues like:
Don't worry if you're not technical, most of the tools and methods I'm going to use are very well documented around the web. Let's meet our volunteers! Here's what I'll be using to do this job:
Here are other checks I've done, but left out in the interest of keeping it short:
My essential reports before I dive in:
Down to business... Architecture Issues1) Important broken linksWe'll always have broken links here and there, and in an ideal world they would all work. Just make sure for SEO & usability that important links (homepage) are always in good shape. The following broken link is on webrevolve homepage that should be pointing to their blog, but returns a 404. This is an important link because it's a great feature and I definitely do want to read more of their content. Fix: Get in there and point that link to the correct page which is http://www.webrevolve.com/our-blog/ How did I find it: Screaming Frog > response codes report 2) Unnecessary RedirectionThis happens a lot more than people like to believe. The problem is that when we 301 a page to a new home we often forget to correct the internal links pointing to the old page (the one with the 301 redirect). This page http://www.lexingtonlaw.com/credit-education/foreclosure.html 301 redirects to http://www.lexingtonlaw.com/credit-education/foreclosure-2.html However, they still have internal links pointing to the old page.
Fix: Get in that CMS and change the internal links to point to http://www.lexingtonlaw.com/credit-education/foreclosure-2.html How did I find it: Screaming Frog > response codes report 3) Multiple subdomains - Canonicalizing the www or non-www versionOne of the first basic principles of SEO, and there are still tons of legacy sites that are tragically splitting their link authority by not using redirecting the www to non-www or vice versa. Sorry to pick on you CVSports :S
Oh, and a couple more have got their way into Google's index that you should remove too:
Basically, you have 7 copies of your site in the index.. Fix: I recommend using www.cvcsports.com as the main page, and you should use your htaccess file to create 301 redirects for all of these subdomains to the main www site. How did I find it? Google query "site:cvcsports.com -www" (I also set my results number to 100 for check through the index quicker) 4) Keeping URL structure consistentIt's important to note that this only becomes a problem when external links are pointing to the wrong URLs. *Almost* every back link is precious, and we want to ensure that we get maximum value from each one. Except we can control how we get linked to; without www, with capitals, or trailing slashes for example. Short of contacting the webmaster to change it, we can always employ 301 redirects to harness as much value as possible. The one place this shouldn't happen is on your own site. We all know that www.example.com/CAPITALS is different to www.example.com/captials when it comes to external link juice. As good SEOs we typically combat human error by having permanent redirect rules to enforce only one version of a URL (ex. forcing lowercase), which may cause unnecessary redirects if someone links in contradiction to redirects. Here are some examples from our sites:
Fix: Determine your URL structure, should they all have trailing slashes, www, lowercase? Whatever you decide, be consistent and you can avoid future problems. Crawl your site, and fix these Indexing & Crawling1) Check for PenaltiesNone of our volunteers have any immediately noticeable penalties, so we can just move on. This is a 2 second check that you must do before trying to nitpick at other issues. How did I do it? Google search queries for exact homepage URL and brand name. If it doesn't show up, you'll have to investigate further. 2) Canonical, noindex, follow, nofollow, robots.txtI always do this so I understand how clued up SEO-wise the developers are, and to gain more insight into the site. You wouldn't check for these tags in detail unless you had just cause (ex. A page that should be ranking isn't I'm going to combine this section as it requires much more than just a quick look, especially on bigger sites. First and foremost check robots.txt and look through some of the blocked directories, try and determine why they are being blocked and which bots they are blocking them from. Next, get Screaming Frog in the mix as it's internal crawl report will automatically check each URL for Meta Data (noindex, header level nofollow & follow) and give you the canonical URL if there happens to be one. If you're spot checking a site, the first thing you should do is understand what tags are in use and why they're using them. Take Webrevolve for instance, they've chosen to NOINDEX,FOLLOW all of their blog author pages.
This is a guess but I think these pages don't provide much value, and are generally not worth seeing in search results. If these were valuable, traffic driving pages, I would suggest they remove NOINDEX but in this case I believe they've made the right choice. They also implement self-serving canonical tags (yes I just made that up), basically each page will have a canonical tag that points to itself. I generally have no problem with this practice as it usually makes it easier for developers. Example: http://www.webrevolve.com/our-work/websites/ecommerce/ 3) Number of pages VS Number of pages indexed by GoogleWhat we really want to know here is how many pages Google has indexed. There's 2 ways of doing this, using Google Webmaster Tools by submitting a sitemap you'll get stats back on how many URLs are actually in the index. OR you can do it without having access but it's much less efficient. This is how I would check...
If the numbers aren't close, like CVCSports (206 pages vs 469 in the index) you probably want to look into it further. I can tell you right now that CVCSports has 206 pages (not counting those that have been blocked by robots.txt). Just by doing this quickly I can tell there's something funny going on and I need to look deeper. Just to cut to the chase, CVCsports has multiple copies of the domain on subdomains which is causing this. Fix: It varies. You could have complicated problems, or it might just be as easy as using canonical, noindex, or 301 redirects. Don't be tempted to block the unwanted pages by robots.txt as this will not remove pages from the index, and will only prevent these pages from being crawled. Duplicate Content & On Page SEOGoogle's Panda update was definitely a game changer, and it caused massive losses for some sites. One of the easiest ways of avoiding at least part of Panda's destructive path is to avoid all duplicate content on your site. 1) Parameter based duplicationURL parameters like search= or keyword= often cause duplication unintentionally. Here's some examples:
Fix: Again, it varies. If I was giving general advice I would say use clean links in the first place - depending on the complexity of the site you might consider 301s, canonical tags or even NOINDEX. Either way, just get rid of them ! How did I find it? Screaming Frog > Internal Crawl > Hash tag column Basically, Screaming Frog will create a unique hexadecimal number based on source code. If you have matching hash tags, you have duplicate source code (exact dupe content). Once you have your crawl ready, use excel to filter it out (complete instructions here). 2) Duplicate Text contentHaving the same text on multiple pages shouldn't be a crime, but post Panda it's better to avoid it completely. I hate to disappoint here, but there's no exact science to finding duplicate text content. Sorry CVCSports, you're up again ;) http://www.copyscape.com/?q=http%3A%2F%2Fwwww.cvcsports.com%2F Don't worry, we've already addressed your issues above, just use 301 redirects to get rid of these copies Fix: Write unique content as much as possible. Or be cheap and stick it in an image, that works too. How did I find it? I used http://www.copyscape.com, but you can also copy & paste text into Google search 3) Duplication caused by paginationPage 1, Page 2, Page 3... You get the picture. Over time, sites can accumulate thousands if not millions of duplicate pages because of those nifty page links. I swear I've seen a site with 300 pages for one product page. Our examples:
Another example?
Fix: General advice is to use the NOINDEX, FOLLOW directive. (This tells Google not to add this page to the index, but crawl through the page). An alternative might be to use the canonical tag but this all depends on the reason why pagination exists. For example, if you had a story that was separated across 3 pages, you definitely would want them all indexed. However, these example pages are pretty thin and *could* be considered as low quality for Google. How did I find it? Screaming Frog > Internal links > Check for pagination parameters Open up the pages and you'll quickly determine if they are auto generated, thin pages. Once you know the pagination parameter or structure of the URL you can check Google's index like so: site:example.com inurl:page= Time's up! There's so much more I wish I could do, but I was strict about the 1 hour time limit. A big thank you to the brave volunteers who put their sites forward for this post. There was one site that just didn't make the cut, mainly because they've done a great job technically, and, um, I couldn't find any technical faults. Now it's time for the community to take some shots at me!
Thanks for reading, you can reach me on Twitter @dsottimano if want to chat and share your secrets ;) Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! |
| You are subscribed to email updates from SEOmoz Daily SEO Blog To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google Inc., 20 West Kinzie, Chicago IL USA 60610 | |
Rule one: You can build a business on the foundation of great customer service.
Rule two: The only way to do great customer service is to treat different customers differently.
The question: Who is your customer?
It's not obvious.
Zappo's is a classic customer service company, and their customer is the person who buys the shoes.
Nike, on the other hand, doesn't care very much at all about the people who buy the shoes, or even the retailers. They care about the athletes (often famous) that wear the shoes, sometimes for money. They name buildings after these athletes, court them, erect statues...
Columbia Records has no idea who buys their music and never has. On the other hand, they understand that their customer is the musician, and they have an entire department devoted to keeping that 'customer' happy. (Their other customer was the program director at the radio station, but we know where that's going...)
Many manufacturers have retailers as their customer. If Wal-Mart is happy, they're happy.
Apple had just one customer. He passed away last year.
And some companies and politicians choose the media as their customer.
If you can only build one statue, who is it going to be a statue of?
[You're getting this note because you subscribed to Seth Godin's blog.]
Don't want to get this email anymore? Click the link below to unsubscribe.
| Your requested content delivery powered by FeedBlitz, LLC, 9 Thoreau Way, Sudbury, MA 01776, USA. +1.978.776.9498 |
Mish's Global Economic Trend Analysis |
| Posted: 05 Feb 2012 02:53 PM PST Blog Redirects Today I learned my blog is being redirected to another URL name in some countries. This is a new "feature" in Blogger that Google added beginning a few weeks back. Instead of exposing a single "Blogger" to the world then censoring it to meet the requirements of local governments, Google decided to mirror content into country-specific domains then redirect users from foreign countries to the mirror associated with their country. If that country decides to censor something, it will somehow be noted on any page so the reader knows they're seeing a filtered view. Readers can also try surfing to the original blog URL by appending /ncr (No Country Redirect) after the main name, such as http://globaleconomicanalysis.blogspot.com/ncr The above approach assumes a country doesn't filter on that pattern and block the request. For example: my blog is blocked in China so appending /ncr is unlikely to accomplish anything. Google's Explanation Why does my blog redirect to a country-specific URL? Q: Why is this happening?Echo Comments Not Working on Redirects I was unaware this was happening until today when readers in New Zealand and Australia informed me that comments were no longer working. Sites With Lost Functionality So Far The "key" within Echo's database that associates comments to a blog entry is the full blog URL (site name + post permanent URL). Filtering off the language code alone is insufficient because for some reason Google changed the suffix for New Zealand from ".com" to ".co". I will get an email into Google to see if they can implement a scheme to only add a suffix. Then I still need to get Echo to do something or alternatively write a Java script to strip off the language code. Anyone using Echo with blogger is going to have these same issues. Twitter Employs "Filtering" as Well Tech Week Europe reports Google To Censor Blogger Sites On Country-By-Country Basis Google follows Twitter's lead and will use country-code top level domains to censor content as required.More Tech Week "Tweet" Articles Twitter Can Now Censor Tweets In Individual Countries  Twitter said that it must begin censoring tweets, if the company was going to continue to continue its international expansion. Twitter has been blocked by a number of governments, including China and the former Egyptian regime after it was used to ignite anti-government protests. Twitter said that it must begin censoring tweets, if the company was going to continue to continue its international expansion. Twitter has been blocked by a number of governments, including China and the former Egyptian regime after it was used to ignite anti-government protests.Twitter Faces Protest Over Censorship Move Judge Rules Twitter Must Hand Over Account Data to Wikileaks Prosecutors Big Brother is watching. However, it's too late to worry about 1984. The worry now is if the next stop is the Year 2525 where "Everything you think do and say is in the pill you took today". Mike "Mish" Shedlock http://globaleconomicanalysis.blogspot.com Click Here To Scroll Thru My Recent Post List Mike "Mish" Shedlock is a registered investment advisor representative for SitkaPacific Capital Management. Sitka Pacific is an asset management firm whose goal is strong performance and low volatility, regardless of market direction. Visit http://www.sitkapacific.com/account_management.html to learn more about wealth management and capital preservation strategies of Sitka Pacific.
|
| Postponed Till "Tomorrow"; Juncker Issues ultimatum "Comply or Default" Posted: 05 Feb 2012 12:02 PM PST It's Groundhog Day once again as Greek crisis talks for debt deal pushed to Monday Coalition backers held a five-hour meeting late Sunday with Prime Minister Lucas Papademos to hammer out a deal with debt inspectors representing eurozone countries and the International Monetary Fund — but again failed to reach an agreement.Juncker Issues ultimatum "Comply or Default" The theater of the absurd continues for yet another day with Juncker's ultimatum: Comply or default Jean-Claude Juncker, the head of the Eurogroup, warned Greece through an interview to a German magazine that it will either comply with its creditors' requirements or default, as it should not expect any additional support from its peers.This is beyond ridiculous. The EU and IMF Need to Stand Up and Announce "Too Late" Deal is OFF, then work with Greece to plan a return to the Drachma. Mike "Mish" Shedlock http://globaleconomicanalysis.blogspot.com Click Here To Scroll Thru My Recent Post List Mike "Mish" Shedlock is a registered investment advisor representative for SitkaPacific Capital Management. Sitka Pacific is an asset management firm whose goal is strong performance and low volatility, regardless of market direction. Visit http://www.sitkapacific.com/account_management.html to learn more about wealth management and capital preservation strategies of Sitka Pacific.
|
| You are subscribed to email updates from Mish's Global Economic Trend Analysis To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google Inc., 20 West Kinzie, Chicago IL USA 60610 | |
How to Build an Advanced Keyword Analysis Report in Excel |
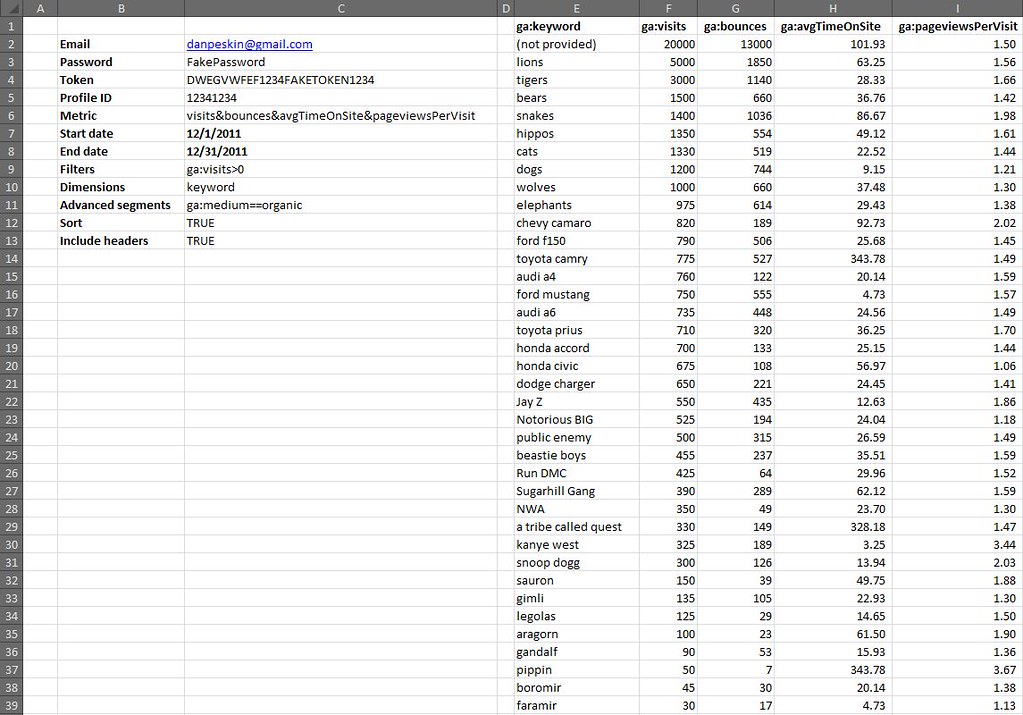
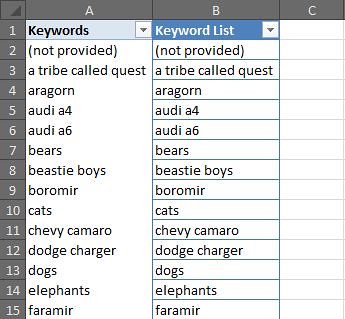
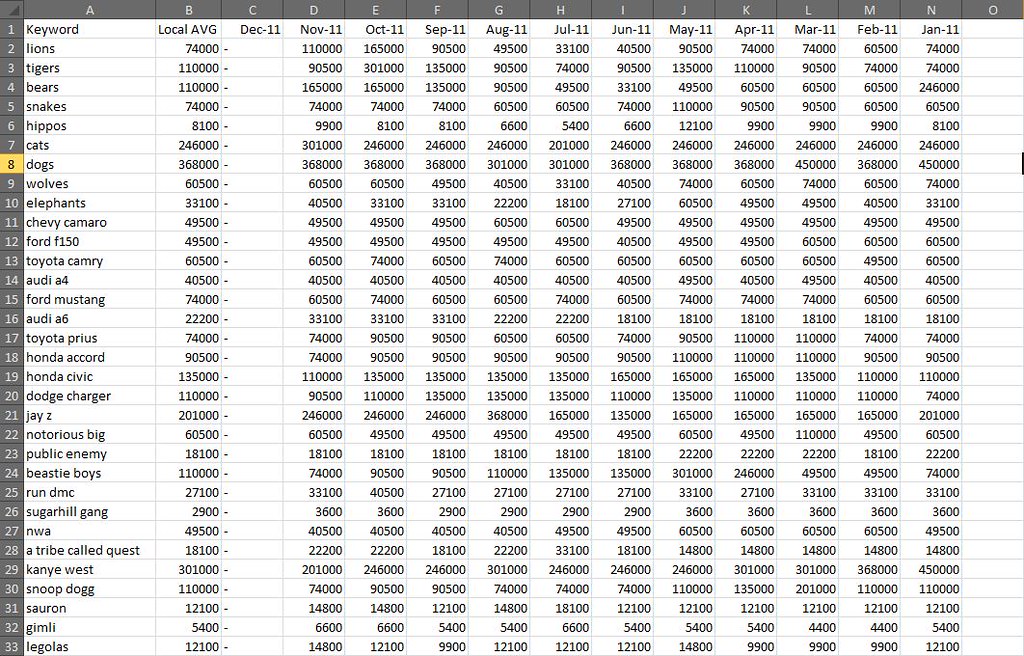
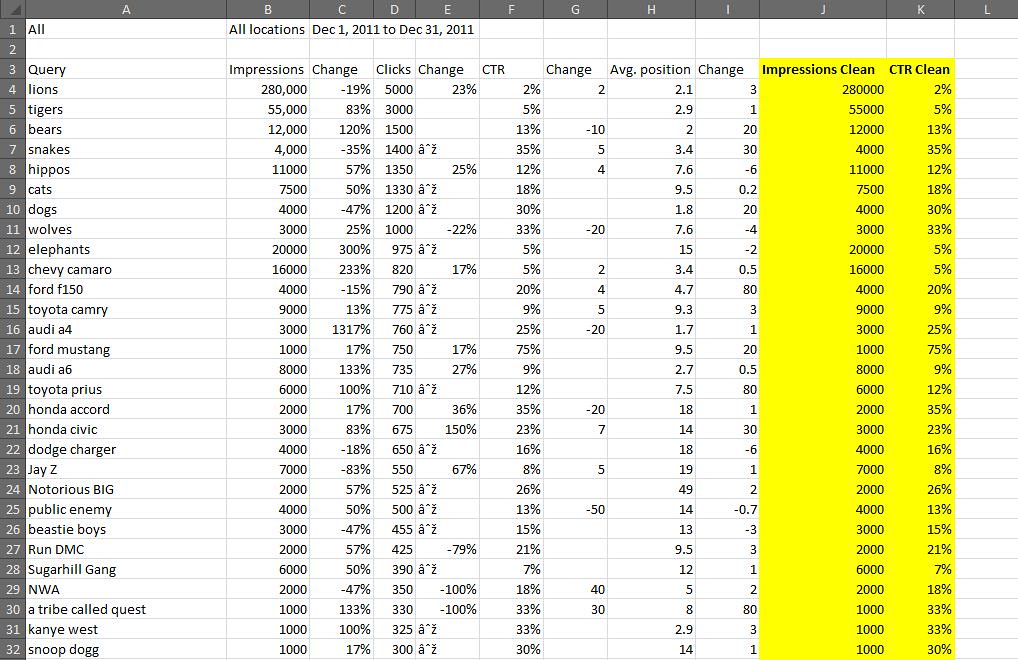
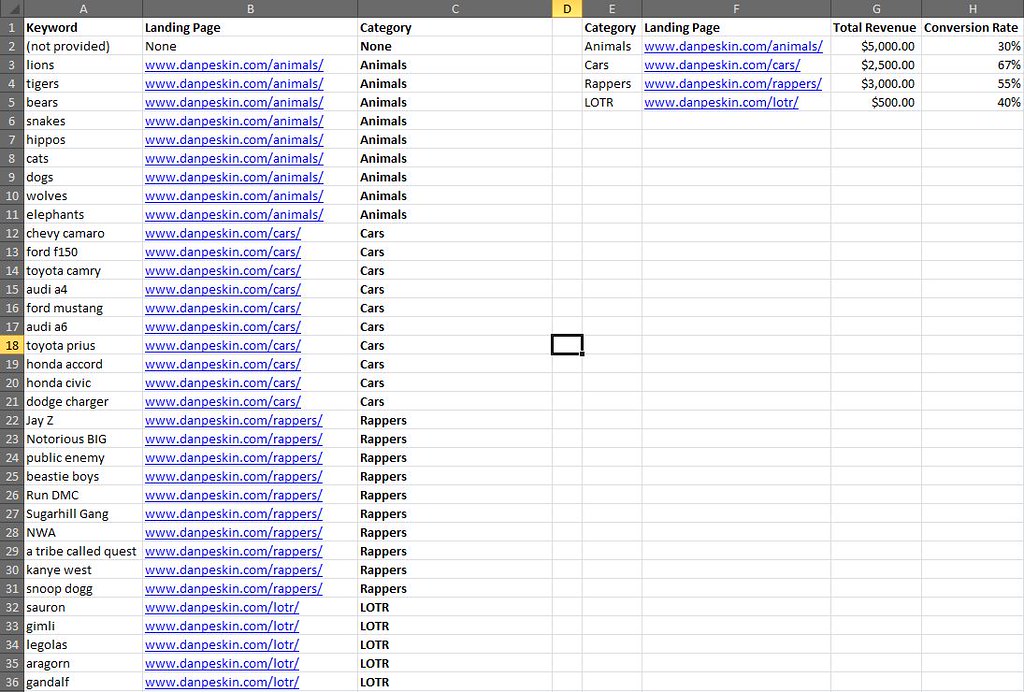
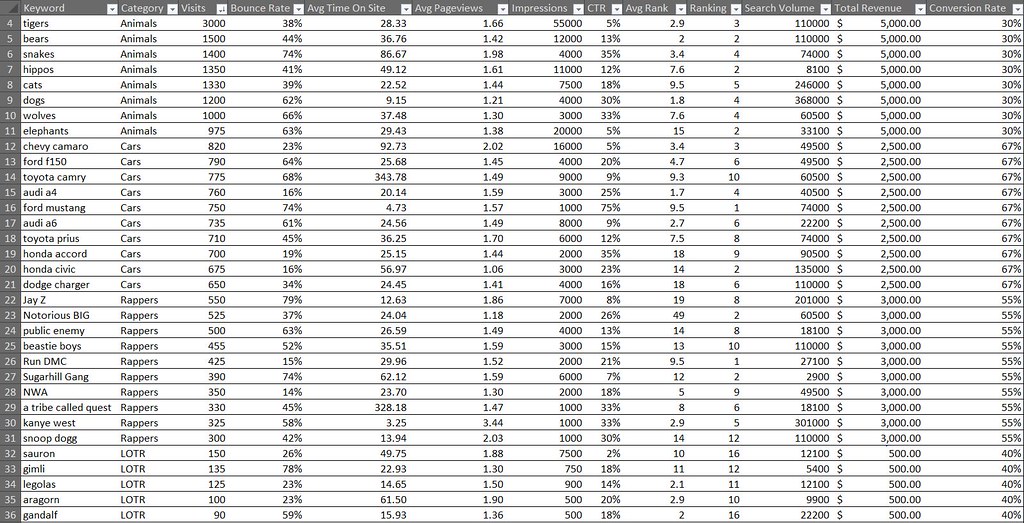
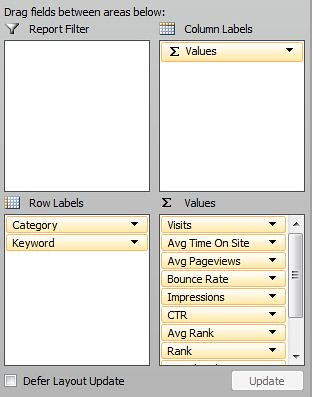
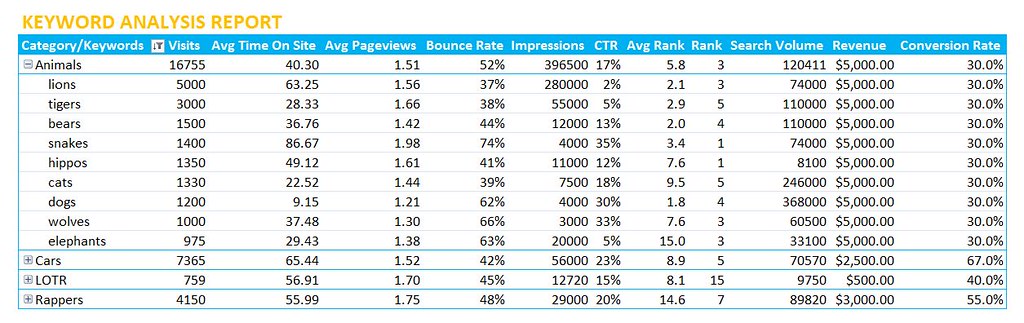
| How to Build an Advanced Keyword Analysis Report in Excel Posted: 04 Feb 2012 12:04 AM PST Posted by Dan Peskin This post was originally in YouMoz, and was promoted to the main blog because it provides great value and interest to our community. The author's views are entirely his or her own and may not reflect the views of SEOmoz, Inc. Analyzing keyword performance, discovering new keyword opportunities, and determining which keywords to focus efforts on can be painstaking when you have thousands of keywords to review. With keyword metrics coming from all over the place (Analytics, Adwords, Webmaster Tools, etc.), it’s challenging to analyze all the data in one place regularly without having to do a decent amount of manual data manipulation. In addition, dependent on your site’s business model, tying revenue metrics to keyword data is a whole other battle. This post will walk you through a solution to these keyword analysis issues and provide some tips on how you can slice and dice your data in wonderful ways. With Microsoft Excel, we can create a report with all the keyword data you will need, all in one place, and fairly easy to update on a weekly or monthly basis. Then with all this data we can easily categorize segments of it to more quickly determine the better performing sets of keywords. What we will need to do is push Google Analytics, Webmaster Tools, Adwords, Ranking data, and Revenue data all into one excel spreadsheet. Then we will put it all together into one master report and one categorized pivot table report. To start, you should be especially familiar with pivot tables, the Google Adwords API, the Google Analytics API, and keyword research of course. Utilizing these APIs and being consistent in the formatting of the data you put into your spreadsheet will make it easy to update. If you aren’t familiar with these tools, I have provided resources below and some steps to organizing this data. Here are some resources for learning to use pivot tables in Excel: Excel for SEO Now let’s go fetch that data. I Got 99 Problems, But A Keyword Visit Ain't OneFirst off we need to get our keyword traffic metrics through the Google Analytics API. I suggest using Mikael Thuneberg’s GA Data Fetch spreadsheet. You can follow the instructions, read the how to guide, and download the file here. Make sure to build off the GA data fetch file or a copy of it, as it has the proper VBA functions (the Visual Basic code that allows for the API to work) installed for API calls. Once you have your API token and the spreadsheet setup you can perform your first API call. We will be using the more complex query to extract organic keyword visits for a specific date field and filter by the number of visits. The query I use for example, will output visits, average time on site, page views, and bounces for any keyword with 5 or more visits in the last 30 days. However, you can modify the parameters to your liking. To see what other metrics can be used, check out the Analytics API documentation. Your Analytics data should look something like this: Google Analytics data called through the API in Excel. Now select the whole keyword column and create a pivot table of the keyword list in another sheet. In the adjacent column create a table where the cells equal the values in the pivot table column. Label this table “KeywordList” or whatever you like. We now have the keyword table to reference for extracting Adwords data. Pivot tables don’t have the same referencing abilities as regular tables, so the table in column B is what you will reference in future steps. To Be, Or Not To Be Searched, That Is The QuestionNext up is pulling in search volumes for our keyword table. Thanks to the wonderful Richard Baxter, there are a couple articles on using and installing the Adwords API Plugin. One on SEOmoz and one on Seogadget. I know the Adwords API access is a bit of an issue for some, so if you cannot use the API, utilize the Google Adwords Keyword Tool (gathering data from this tool will unfortunately require a lot more work). In a new sheet, use the Adwords API array formula called “arrayGetAdWordsStats” to pull in the average and seasonal monthly search volumes for your keyword table. Your formula should look something like this: =arrayGetAdWordsStats(KeywordList,”EXACT”,”US”,”WEB”) You should now have 12 months of historical search volumes and averages for all your keywords. Results from an Adwords API call usually look like this. Note: If your keyword list is greater than 800 keywords, you will have to break out the list into a few separate tables just to perform API calls for those keywords. If this is the case, make sure to keep each array of search volumes aligned in the same columns. The Impression That I GetNo API required here, Google’s Webmaster Tools provides a pretty easy way to download its search query data. If you open up the Search Queries report in Webmaster Tools there is an option to “download the table” at the bottom. Download the table for the same date range you used earlier and drop it into a new sheet. The report downloaded from Webmaster Tools. Note the “-“ is used for zero values, in the yellow columns I simply cleaned that up with an IF statement. Impressions, CTR, and Average Rank can now been added to our metrics. If You Ain't First Page, You're LastSince we all know how accurate average rank is from Webmaster Tools, let’s get some current rankings into this report .Grab your main keyword list from the spreadsheet and run rankings for them with your application of choice. I usually use Rank Tracker, but I am sure everyone has their own preference. Once you have your rankings drop it into a new sheet. The More You KnowThe number of metrics we can add to the report are limitless, but there comes a point where adding too many can create more work for updating the report or create analysis paralysis. The only other metric I suggest adding in is the SEOmoz Keyword Difficulty if you have a PRO account. Again this may be very time consuming to add for large numbers of keywords, hopefully you have an intern for that. Mo Money Mo MetricsRevenue data may come from different places dependent on how your business works, so I unfortunately don’t have a one stop solution to importing that data. However, most applications usually allow you to download that data to CSV or Excel. If you have Ecommerce enabled in Google Analytics, you can use the API to pull in this data. As long as you have some metrics to relate to your keyword such as Average Order Value or Conversion Rate, drop it in a new sheet and you will be good to go. Some of you may be asking yourself what to do if your revenue data does not tie back to the keyword visit. This is where the categorization of keywords plays an extremely important part in this report. In this case, we want to create a bridge between the revenue data and keyword data. This can be done through categorizing your keywords into a category that relates back to a field in your revenue data. For example, you might be able to associate keywords with product names or landing pages. These products or landing pages would then become categories. Once you have determined what your categories will be, you can assign them to keywords in a new sheet that simply contains keywords in one column and the category tag in the other. You can learn more about keyword categorization here. Categorizing the keywords above not only lets me group them to aggregate metrics for analysis, but it allows me to bridge the gap somewhat between the keywords and conversions in this example. One Report To Rule Them AllFinally we have all the data; we just have to put it all together. Create a new sheet and pull in your master keyword list by using =NameOfTheTable, drag this down until you reach the last keyword on the list (paste values after if you want sorting capabilities). Now select your keywords and create a new table. In the columns next to the keywords all you have to do is a VLOOKUP of each metric you would like to add to your report. Once you fill in the first cell of each column, the column should automatically be added to the table and populate the other cells with the equation. Repeat this process until all your metrics are in this table. There will also be a need to calculate some metrics such as the Bounce Rate or Conversion Rate if you pulled in revenue data. Those should be added in adjacent columns as well. Additionally, if you didn’t need to categorize your keywords earlier, I suggest categorizing them now in an adjacent column. When completed your master report should look something like this: The master report. Amazing. We have all the data in one place in a simple to sort and use table! Just wait…it gets better. Pivotal SuccessNow you may be wondering how this report can get any better. Two words my friends: Pivot Tables. Creating a pivot table of your master report will allow you to segment your data in a number of ways that weren’t possible before. In the Pivot Table Field List, the Row Labels, Column Labels, and Values will define the layout of your report. What we first need to do is drag and drop the Category and Keyword fields into the Row Labels respectively. This will set your top level metrics to summarize at the Category level and allow you to drill down into each Category to see the associated keywords and their individual metrics. Next you will want to start dragging your metrics into the Values section, which will automatically populate the Column Labels section with the Values field. As you add your metrics in, you can edit their names and the way they are aggregated. You will want to think carefully about how you will aggregate certain metrics so that viewing those summarized numbers at a Category level makes sense. This shows you how best to setup your pivot table fields and their value settings. For instance, I might summarize Impressions and Visits, but average CTR and Bounce Rate. Seeing the average CTR and Bounce Rate for a Category will allow me to narrow down which sets of keywords are performing better than others. Then looking at the total Impressions and Visits for those well performing categories will allow me to see where there might be a higher potential to increase traffic to my site. While this may not be an absolute rule to determine keyword focus, it is a good rule of thumb and can be a way to prioritize which ones to focus on. Pivot table reports also allow you to add report filters, letting you filter out data by any metric or even multiple metrics. With this you could analyze keywords that only rank on the first page of SERPs using the current ranking as a filter. Hell, you could add a field to the master report calculating the number of words in each keyword phrase, then filter by that and bounce rate, giving you your well performing long tail keywords. Get creative, let loose, play with the metrics, you will be surprised at what kind of conclusions you can make about your site’s keyword traffic. The final product. ConclusionUpdating the report is simple. Rerun the API calls with the new date range, rerun your rankings for the new keyword list, and export the other reports you need with new date range. As long as you kept your formatting and equations the same, the rankings and other reports should be dropped into their respective sheets without having to change anything. The master report should automatically be updated once you update the keyword column and the pivot report should update once you hit refresh under the pivot table menu. That’s it! Well I should probably stop talking now and let you get to your hours upon hours of keyword analysis fun. Hopefully this was informative enough to make building a report such as this fairly easy. I would love to hear your feedback and will gladly answer any questions or comments about the post below. If you have issues later on, you can always contact me via Twitter. Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read! |
| You are subscribed to email updates from SEOmoz Daily SEO Blog To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google Inc., 20 West Kinzie, Chicago IL USA 60610 | |
Good luck with that, there aren't any.
If you hesitate when leaping from rope to another, you're not going to last very long.
And this is at the heart of what makes innovation work in organizations, why industries die, and how painful it is to try to maintain the status quo while also participating in a revolution.
Gather up as much speed as you can, find a path and let go. You can't get to the next rope if you're still holding on to this one.
[You're getting this note because you subscribed to Seth Godin's blog.]
Don't want to get this email anymore? Click the link below to unsubscribe.
| Your requested content delivery powered by FeedBlitz, LLC, 9 Thoreau Way, Sudbury, MA 01776, USA. +1.978.776.9498 |