Posted by MatthewBarby
As digital marketers, big data should be what we use to inform a lot of the decisions we make. Using intelligence to understand what works within your industry is absolutely crucial within content campaigns, but it blows my mind to know that so many businesses aren't focusing on it.
One reason I often hear from businesses is that they don't have the budget to invest in complex and expensive tools that can feed in reams of data to them. That said, you don't always need to invest in expensive tools to gather valuable intelligence — this is where data scraping comes in.
Just so you understand, here's a very brief overview of what data scraping is from Wikipedia:
"Data scraping is a technique in which a computer program extracts data from human-readable output coming from another program."
Essentially, it involves crawling through a web page and gathering nuggets of information that you can use for your analysis. For example, you could search through a site like Search Engine Land and scrape the author names of each of the posts that have been published, and then you could correlate this to social share data to find who the top performing authors are on that website.
Hopefully, you can start to see how this data can be valuable. What's more, it doesn't require any coding knowledge — if you're able to follow my simple instructions, you can start gathering information that will inform your content campaigns. I've recently used this research to help me get a post published on the front page of BuzzFeed, getting viewed over 100,000 times and channeling a huge amount of traffic through to my blog.
Disclaimer: One thing that I really need to stress before you read on is the fact that scraping a website may breach its terms of service. You should ensure that this isn't the case before carrying out any scraping activities. For example, Twitter completely prohibits the scraping of information on their site. This is from their Terms of Service:
"crawling the Services is permissible if done in accordance with the provisions of the robots.txt file, however, scraping the Services without the prior consent of Twitter is expressly prohibited"
Google similarly forbids the scraping of content from their web properties:
Google's Terms of Service do not allow the sending of automated queries of any sort to our system without express permission in advance from Google.
So be careful, kids.
Content analysis
Mastering the basics of data scraping will open up a whole new world of possibilities for content analysis. I'd advise any content marketer (or at least a member of their team) to get clued up on this.
Before I get started on the specific examples, you'll need to ensure that you have Microsoft Excel on your computer (everyone should have Excel!) and also the SEO Tools plugin for Excel (free download here). I put together a full tutorial on using the SEO tools plugin that you may also be interested in.
Alongside this, you'll want a web crawling tool like Screaming Frog's SEO Spider or Xenu Link Sleuth (both have free options). Once you've got these set up, you'll be able to do everything that I outline below.
So here are some ways in which you can use scraping to analyse content and how this can be applied into your content marketing campaigns:
1. Finding the different authors of a blog
Analysing big publications and blogs to find who the influential authors are can give you some really valuable data. Once you have a list of all the authors on a blog, you can find out which of those have created content that has performed well on social media, had a lot of engagement within the comments and also gather extra stats around their social following, etc.
I use this information on a daily basis to build relationships with influential writers and get my content placed on top tier websites. Here's how you can do it:
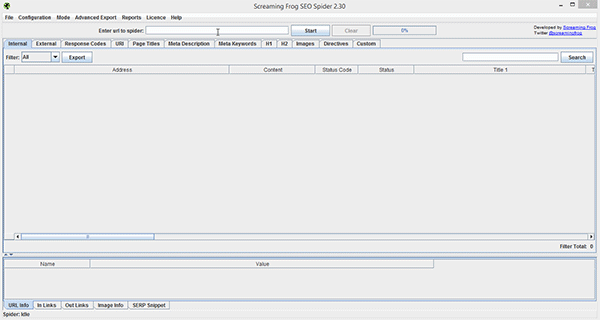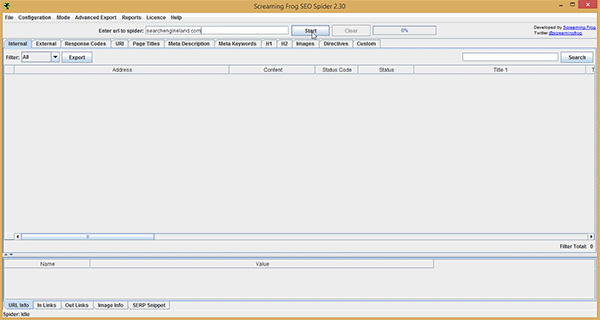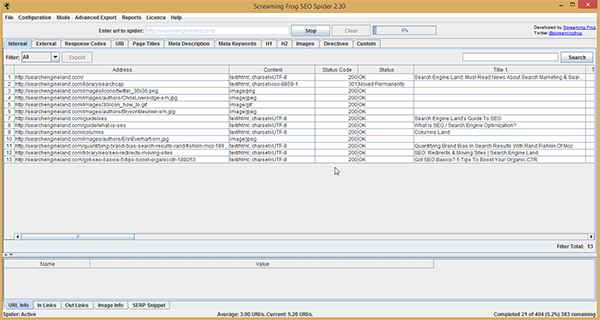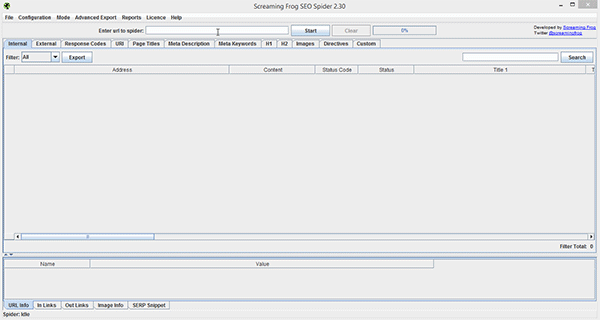
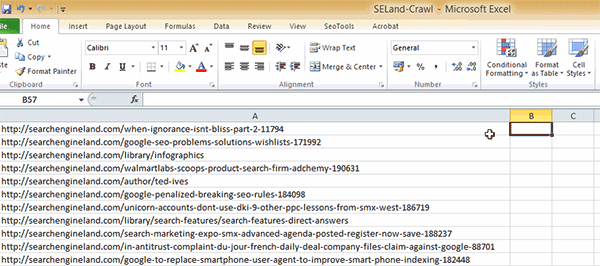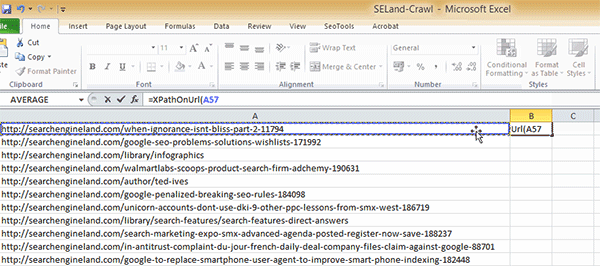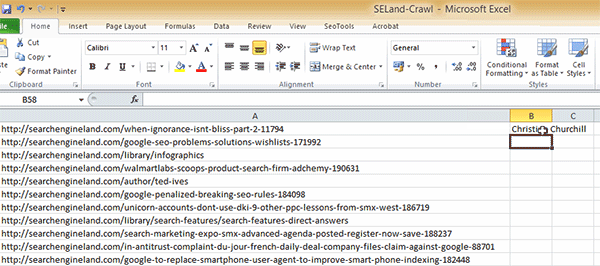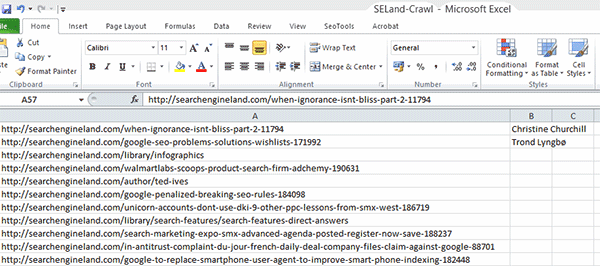
Step 1: Gather a list of the URLs from the domain you're analysing using Screaming Frog's SEO Spider. Simply add the root domain into Screaming Frog's interface and hit start (if you haven't used this tool before, you can check out my tutorial here).
Once the tool has finished gathering all the URLs (this can take a little while for big websites), simply export them all to an Excel spreadsheet.
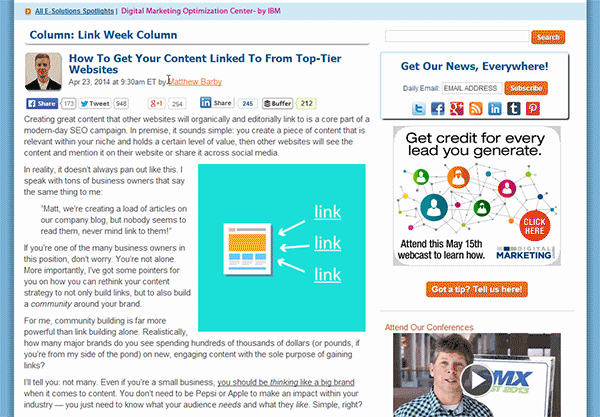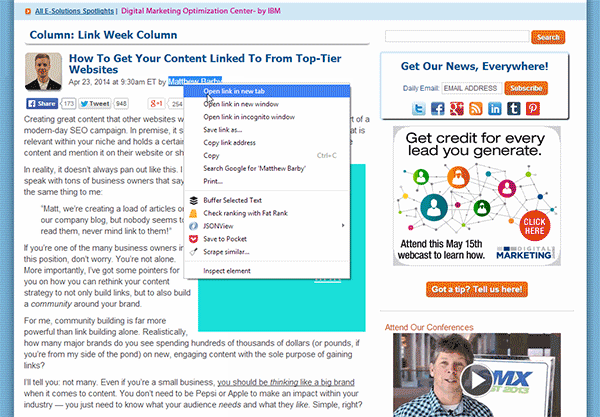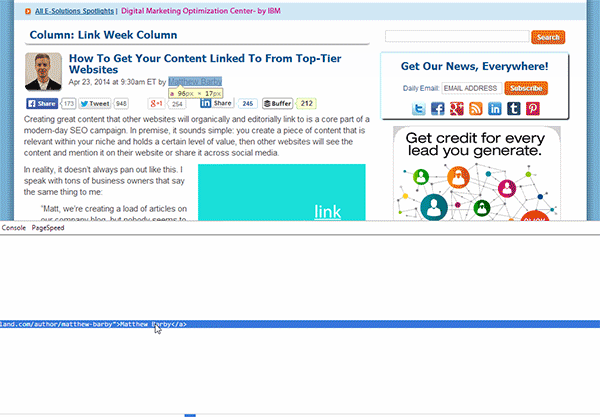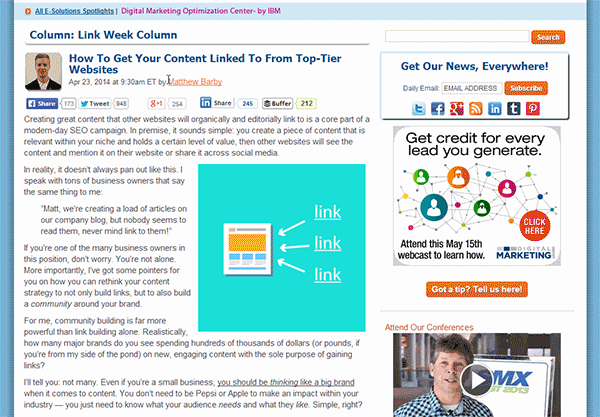
Step 2: Open up Google Chrome and navigate to one of the article pages of the domain you're analysing and find where they mention the author's name (this is usually within an author bio section or underneath the post title). Once you've found this, right-click their name and select inspect element (this will bring up the Chrome developer console).
Within the developer console, the line of code associated to the author's name that you selected will be highlighted (see the below image). All you need to do now is right-click on the highlighted line of code and press Copy XPath.
For the Search Engine Land website, the following code would be copied:
//*[@id="leftCol"]/div[2]/p/span/a
This may not make any sense to you at this stage, but bear with me and you'll see how it works.
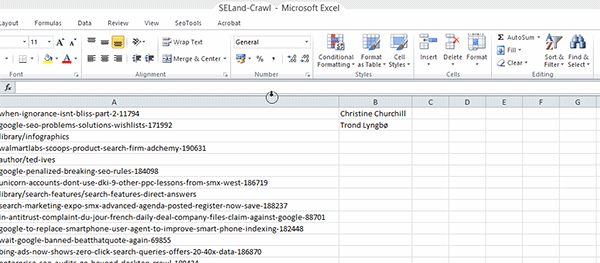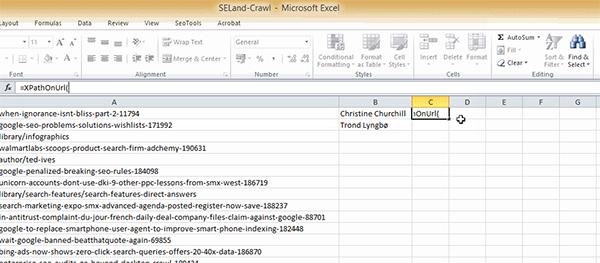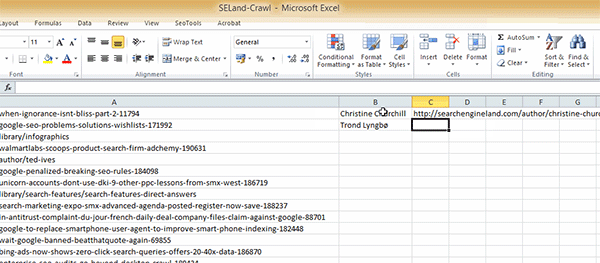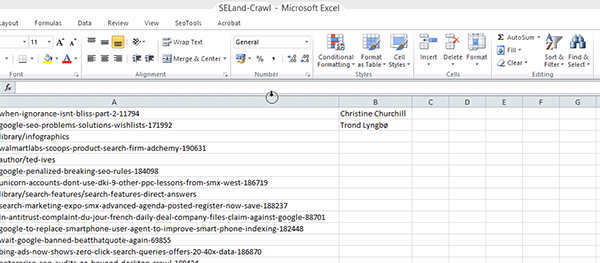
Step 3: Go back to your spreadsheet of URLs and get rid of all the extra information that Screaming Frog gives you, leaving just the list of raw URLs – add these to the first column (column A) of your worksheet.
Step 4: In cell B2, add the following formula:
=XPathOnUrl(A2,"//*[@id='leftCol']/div[2]/p/span/a")
Just to break this formula down for you, the function XPathOnUrl allows you to use the XPath code directly within (this is with the SEO Tools plugin installed; it won't work without this). The first element of the function specifies which URL we are going to scrape. In this instance I've selected cell A2, which contains a URL from the crawl I did within Screaming Frog (alternatively, you could just type the URL, making sure that you wrap it within quotation marks).
Finally, the last part of the function is our XPath code that we gathered. One thing to note is that you have to remove the quotation marks from the code and replace them with apostrophes. In this example, I'm referring to the "leftCol" section, which I've changed to 'leftCol' — if you don't do this, Excel won't read the formula correctly.
Once you press enter, there may be a couple of seconds delay whilst the SEO Tools plugin crawls the page, then it will return a result. It's worth mentioning that within the example I've given above, we're looking for author names on article pages, so if I try to run this on a URL that isn't an article (e.g. the homepage) I will get an error.
For those interested, the XPath code itself works by starting at the top of the code of the URL specified and following the instructions outlined to find on-page elements and return results. So, for the following code:
//*[@id='leftCol']/div[2]/p/span/a
We're telling it to look for any element (//*) that has an id of leftCol (@id='leftCol') and then go down to the second div tag after this (div[2]), followed by a p tag, a span tag and finally, an a tag (/p/span/a). The result returned should be the text within this a tag.
Don't worry if you don't understand this, but if you do, it will help you to create your own XPath. For example, if you wanted to grab the output of an a tag that has rel=author attached to it (another great way of finding page authors), then you could use some XPath that looked a little something like this:
//a[@rel='author']
As a full formula within Excel it would look something like this:
=XPathOnUrl(A2,"//a[@rel='author']")
Once you've created the formula, you can drag it down and apply it to a large number of URLs all at once. This is a huge time-saver as you'd have to manually go through each website and copy/paste each author to get the same results without scraping – I don't need to explain how long this would take.
Now that I've explained the basics, I'll show you some other ways in which scraping can be used…
2. Finding extra details around page authors
So, we've found a list of author names, which is great, but to really get some more insight into the authors we will need more data. Again, this can often be scraped from the website you're analysing.
Most blogs/publications that list the names of the article author will actually have individual author pages. Again, using Search Engine Land as an example, if you click my name at the top of this post you will be taken to a page that has more details on me, including my Twitter profile, Google+ profile and LinkedIn profile. This is the kind of data that I'd want to gather because it gives me a point of contact for the author I'm looking to get in touch with.
Here's how you can do it.
Step 1: First we need to get the author profile URLs so that we can scrape the extra details off of them. To do this, you can use the same approach to find the author's name, with just a little addition to the formula:
=XPathOnUrl(A2,"//a[@rel='author']", <strong>"href"</strong>)
The addition of the "href" part of the formula will extract the output of the href attribute of the atag. In Lehman terms, it will find the hyperlink attached to the author name and return that URL as a result.
Step 2: Now that we have the author profile page URLs, you can go on and gather the social media profiles. Instead of scraping the article URLs, we'll be using the profile URLs.
So, like last time, we need to find the XPath code to gather the Twitter, Google+ and LinkedIn links. To do this, open up Google Chrome and navigate to one of the author profile pages, right-click on the Twitter link and select Inspect Element.
Once you've done this, hover over the highlighted line of code within Chrome's developer tools, right-click and select Copy XPath.
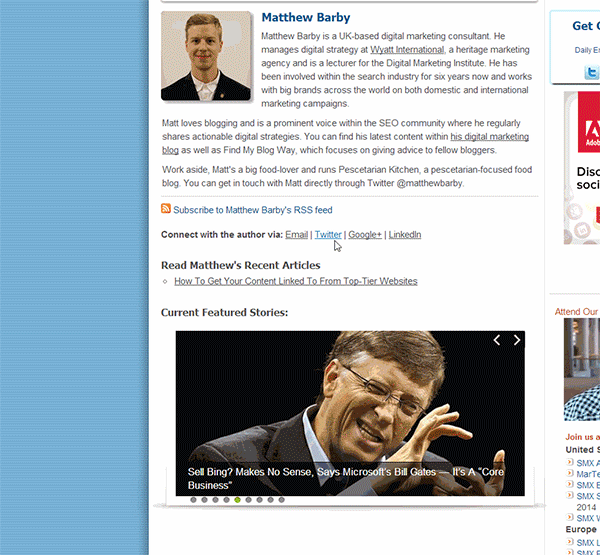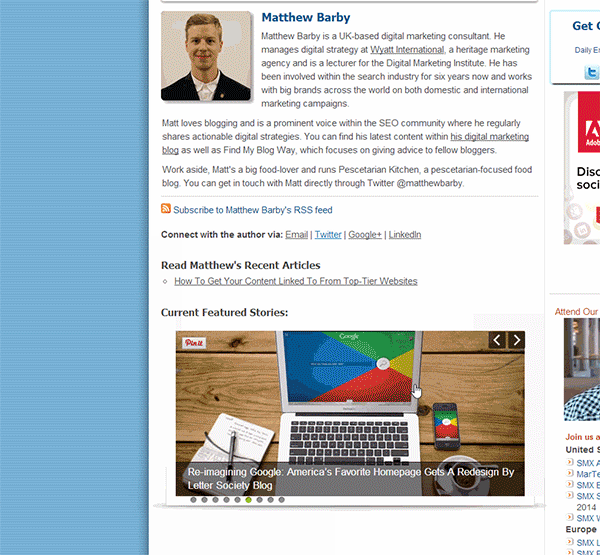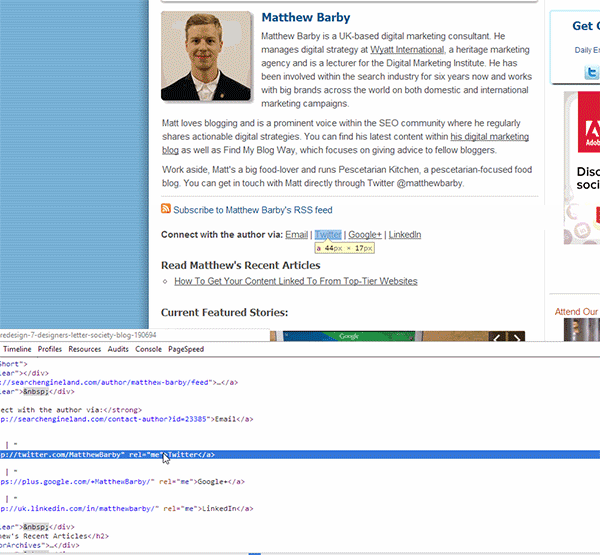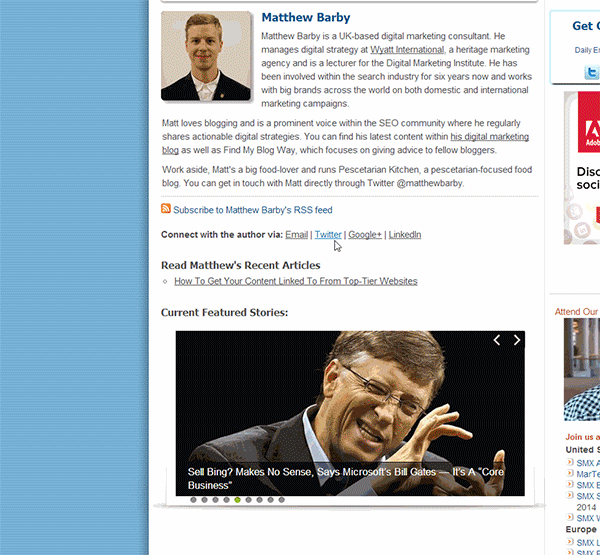
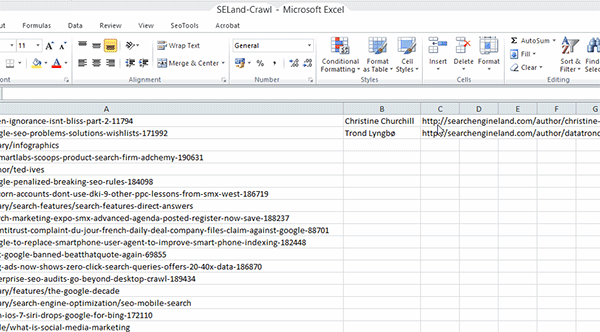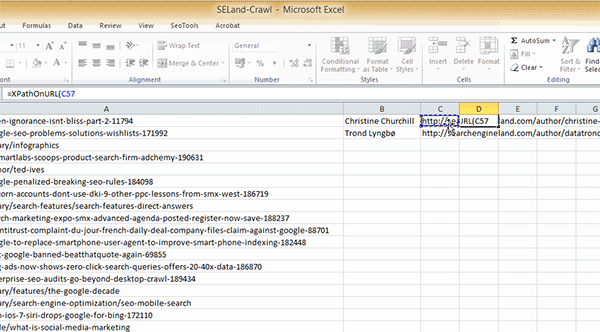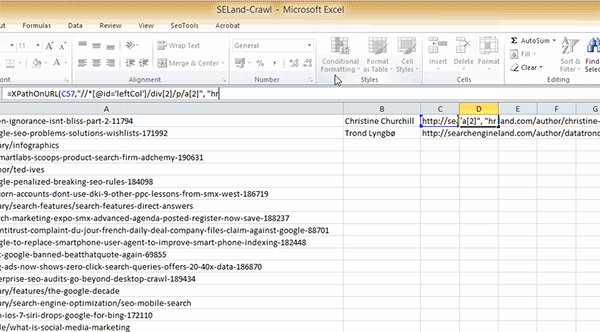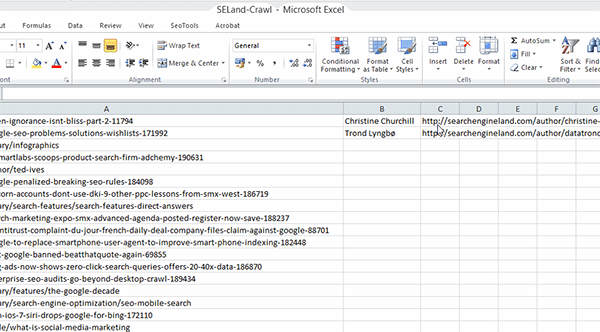
Step 3: Finally, open up your Excel spreadsheet and add in the following formula (using the XPath that you've copied over):
=XPathOnUrl(C2,"//*[@id='leftCol']/div[2]/p/a[2]", "href")
Remember that this is the code for scraping Search Engine Land, so if you're doing this on a different website, it will almost certainly be different. One important thing to highlight here is that I've selected cell C2 here, which contains the URL of the author profile page and not just the article page. As well as this, you'll notice that I've included "href" at the end because we want the actual Twitter profile URL and not just the words 'Twitter'.
You can now repeat this same process to get the Google+ and LinkedIn profile URLs and add it to your spreadsheet. Hopefully you're starting to see the value in this, and how it can be used to gather a lot of intelligence that can be used for all kinds of online activity, not least your SEO and social media campaigns.
3. Gathering the follower counts across social networks
Now that we have the author's social media accounts, it makes sense to get their follower counts so that they can be ranked based on influence within the spreadsheet.
Here are the final XPath formulae that you can plug straight into Excel for each network to get their follower counts. All you'll need to do is replace the text INSERT SOCIAL PROFILE URL with the cell reference to the Google+/LinkedIn URL:
Google+:
=XPathOnUrl(<strong>INSERTGOOGLEPROFILEURL</strong>,"//span[@class='BOfSxb']")
LinkedIn:
=XPathOnUrl(<strong>INSERTLINKEDINURL</strong>,"//dd[@class='overview-connections']/p/strong")
4. Scraping page titles
Once you've got a list of URLs, you're going to want to get an idea of what the content is actually about. Using this quick bit of XPath against any URL will display the title of the page:
=XPathOnUrl(A2,"//title")
To be fair, if you're using the SEO Tools plugin for Excel then you can just use the built-in feature to scrape page titles, but it's always handy to know how to do it manually!
A nice extra touch for analysis is to look at the number of words used within the page titles. To do this, use the following formula:
=CountWords(A2)
From this you can get an understanding of what the optimum title length of a post within a website is. This is really handy if you're pitching an article to a specific publication. If you make the post the best possible fit for the site and back up your decisions with historical data, you stand a much better chance of success.
Taking this a step further, you can gather the social shares for each URL using the following functions:
Twitter:
=TwitterCount(<strong>INSERTURLHERE</strong>)
Facebook:
=FacebookLikes(<strong>INSERTURLHERE</strong>)
Google+:
=GooglePlusCount(<strong>INSERTURLHERE</strong>)
Note: You can also use a tool like URL Profiler to pull in this data, which is much better for large data sets. The tool also helps you to gather large chunks of data from other social networks, link data sources like Ahrefs, Majestic SEO and Moz, which is awesome.
If you want to get even more social stats then you can use the SharedCount API, and this is how you go about doing it…
Firstly, create a new column in your Excel spreadsheet and add the following formula (where A2 is the URL of the webpage you want to gather social stats for):
=CONCATENATE("http://api.sharedcount.com/?url=",A2) You should now have a cell that contains your webpage URL prefixed with the SharedCount API URL. This is what we will use to gather social stats. Now here's the Excel formula to use for each network (where B2 is the cell that contaiins the formula above):
StumbleUpon:
=JsonPathOnUrl(B2,"StumbleUpon")
Reddit:
=JsonPathOnUrl(B2,"Reddit")
Delicious:
=JsonPathOnUrl(B2,"Delicious")
Digg:
=JsonPathOnUrl(B2,"Diggs")
Pinterest:
=JsonPathOnUrl(B2,"Pinterest")
LinkedIn:
=JsonPathOnUrl(B2,"Linkedin")
Facebook Shares:
=JsonPathOnUrl(B2,"Facebook.share_count")
Facebook Comments:
=JsonPathOnUrl(B2,"Facebook.comment_count")
Once you have this data, you can start looking much deeper into the elements of a successful post. Here's an example of a chart that I created around a large sample of articles that I analysed within Upworthy.com.
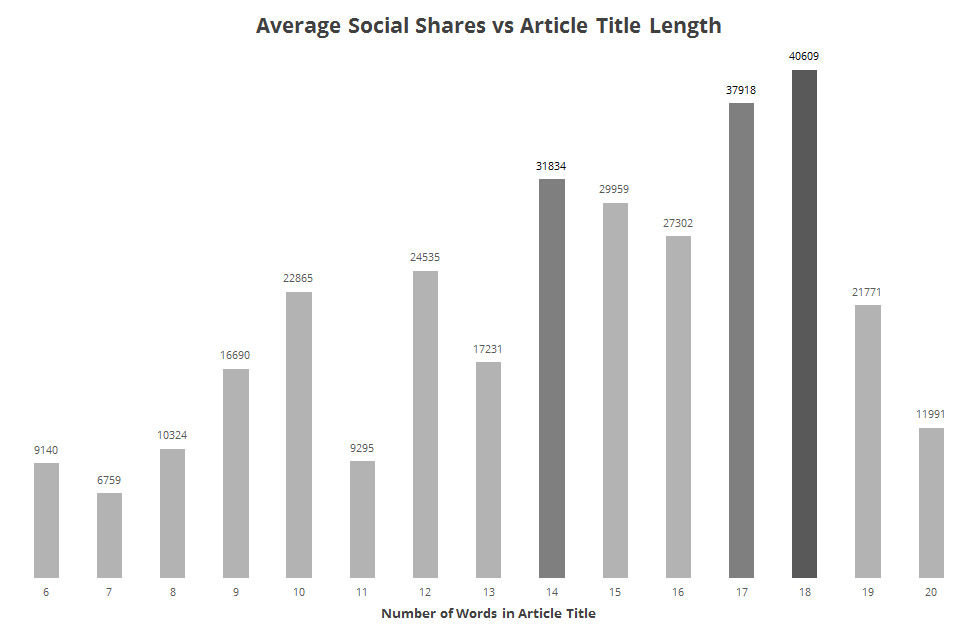
The chart looks at the average number of social shares that an article on Upworthy receives vs the number of words within its title. This is invaluable data that can be used across a whole host of different on-page elements to get the perfect article template for the site you're pitching to.
See, big data is useful!
5. Date/time the post was published
Along with analysing the details of headlines that are working within a site, you may want to look at the optimal posting times for best results. This is something that I regularly do within my blogs to ensure that I'm getting the best possible return from the time I spend writing.
Every site is different, which makes it very difficult for an automated, one-size-fits-all tool to gather this information. Some sites will have this data within the <head> section of their webpages, but others will display it directly under the article headline. Again, Search Engine Land is a perfect example of a website doing this…
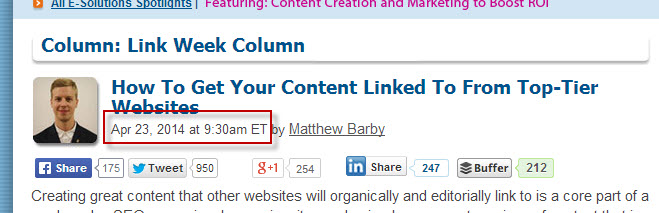
So here's how you can scrape this information from the articles on Search Engine Land:
=XPathOnUrl(<strong>INSERTARTICLEURL</strong>,"//*[@class='dateline']/text()")
Now you've got the date and time of the post. You may want to trim this down and reformat it for your data analysis, but you've got it all in Excel so that should be pretty easy.
Extra reading
Data scraping is seriously powerful, and once you've had a bit of a play around with it you'll also realise that it's not that complicated. The examples that I've given are just a starting point but once you get your creative head on, you'll soon start to see the opportunities that arise from this intelligence.
Here's some extra reading that you might find useful:
TL;DR
- Start using actual data to inform your content campaigns instead of going on your gut feeling.
- Gather intelligence around specific domains you want to target for content placement and create the perfect post for their audience.
- Get clued up on XPath and JSON through using the SEO Tools plugin for Excel.
- Spend more time analysing what content will get you results as opposed to what sites will give you links!
- Check the website's ToS before scraping.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!

























































