tag and also part of the target attribute." In this particular case, the Twitter handles were the only element that could be scraped based on our formula and how it was originally written within the HTML, but sometimes that's not the case. What if we were looking for travel bloggers and came across a site like the one seen below, where our desired Twitter handles are within a text paragraph?
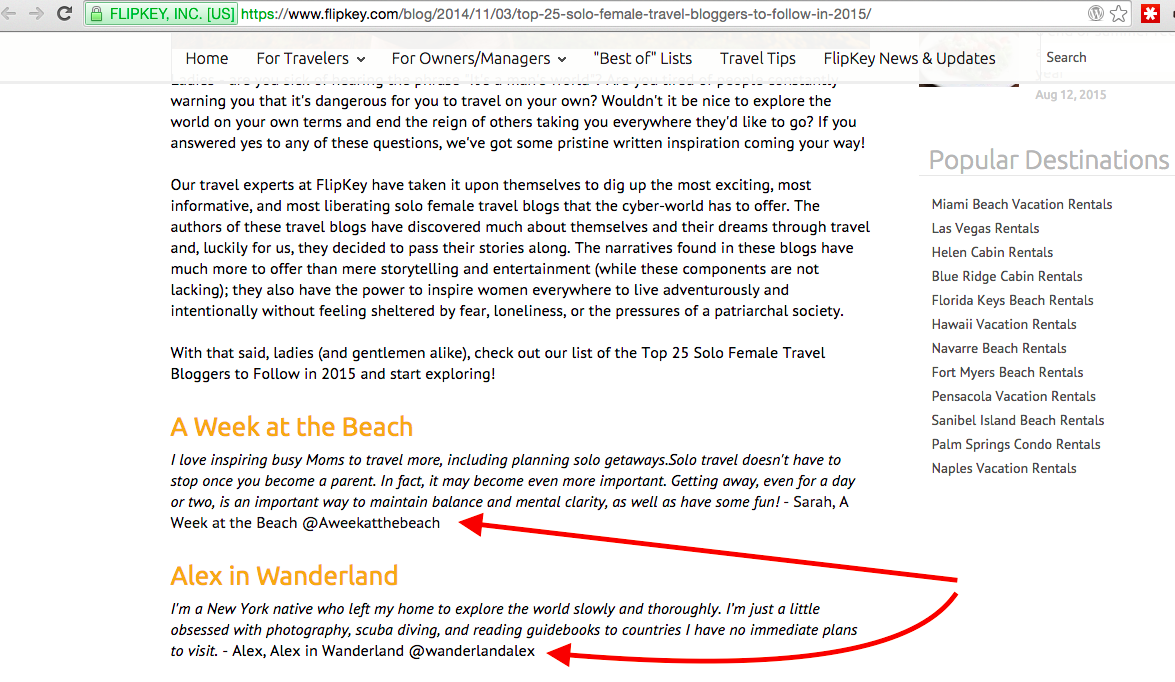
Taking a look at the Inspect Element button, we see the following information:
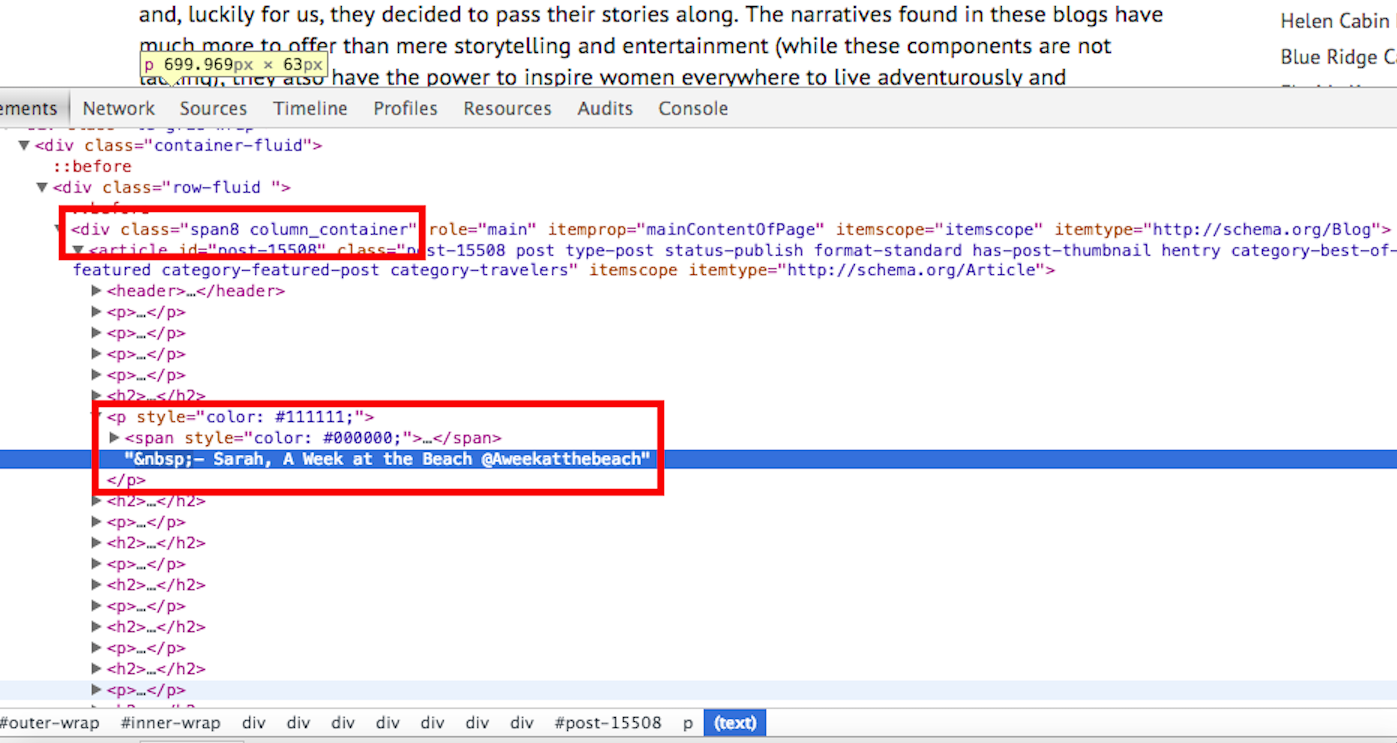
In the top rectangle is the div and the class we need, and in the second rectangle is the other half of the information we require: the
tag. The
tag is used in html to specify where a given paragraph is. The Twitter handles we're looking for are located within a text paragraph, so we'll need to select the
tag as the element to scrape.
Once again, we input the URL into a cell (any empty cell works) and write out the new formula =IMPORTXML(A1, "//div[@class='span8 column_container']//p"). Instead of selecting all of the h3 elements like in the preceding example, this time we're finding all of the
tags within the div elements that have a class of "span8 column_container". The reason we're looking for
tags within div elements that have a class of "span8 column_container" is because there are other
tags on the page that contain information we likely won't need. All of the Twitter handles are contained with
tags within that specifically-classed div, so by selecting it, we'll have selected the most appropriate data.
However, the results of this are not perfect and look like this:
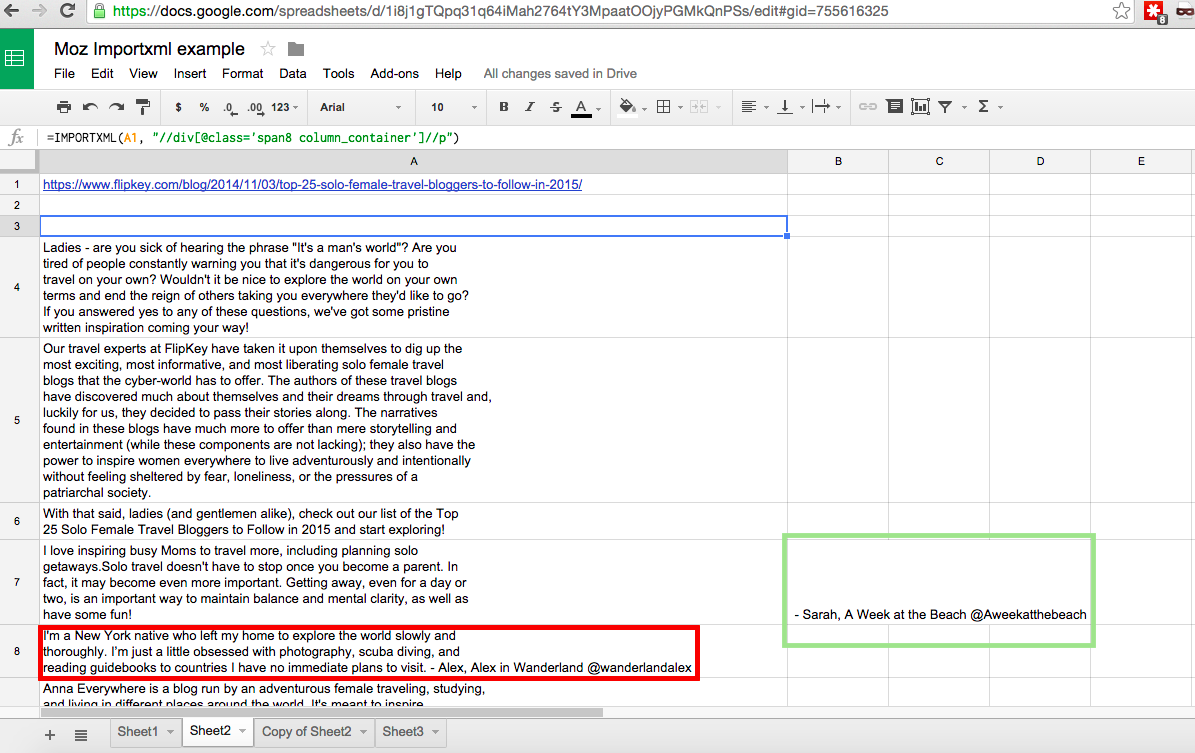
The results are less than ideal, but manageable nonetheless - we ultimately just want Twitter handles, but are provided with a whole bunch of other text. Highlighted in the green rectangle is a result closer to what I want, but not in the column I need (there's also another one down the page out of the view of the screenshot, but most are where I need them). To make sure we get all the data in the appropriate format, we can copy and paste values for everything within columns A–C, which will remove the values populated by formulas and replace them with hard values that can be manipulated. Once that is done, we can cut and paste the outlying values (one in column B and one in column C) into their corresponding cells in column A.
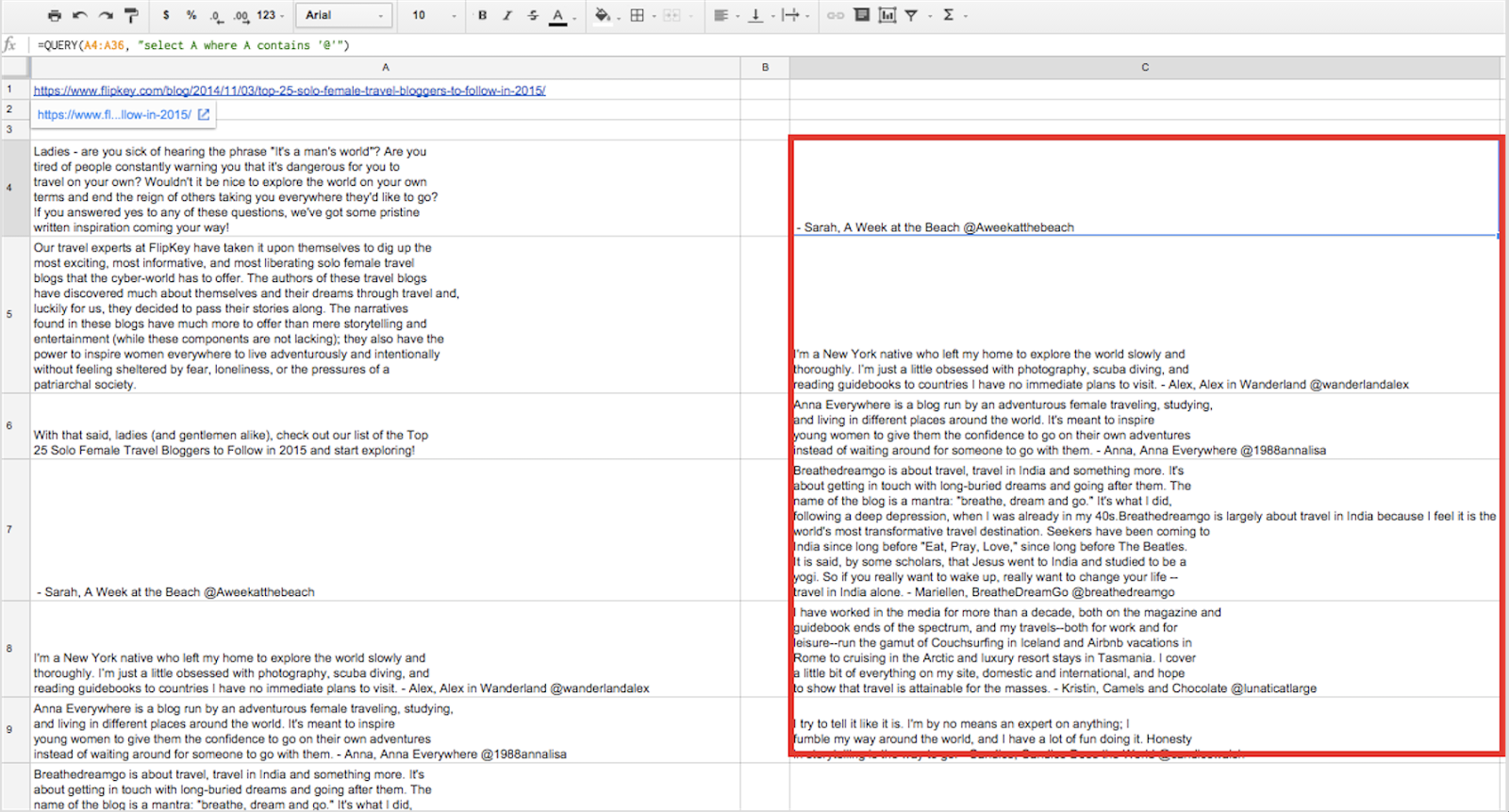
All of our data is now in column A; however, some of the cells include information that does not contain a Twitter handle. We're going to fix this by running the =QUERY function and separating the cells that contain "@" from the ones that do not. In a separate cell (I used cell C4), we're going to input =query(A4:A36, or "Select A where A contains '@'") and hit enter. BOOM. From here on, we'll have only cells that contain Twitter handles, a huge improvement over having a mixed bag of results that contain both cells with and without Twitter handles. To explain, our formula can be translated as "From within the array A4:A36, select the cell in column A when that cell contains '@'." It's pretty self-explanatory, but is nonetheless a fantastic formula that is incredibly powerful. The image below shows what this looks like:
Keep in mind that the results we just pulled are going to contain excess information within the cells that we'll need to remove. To do this, we'll need to run the =REGEXEXTRACT formula, which will pretty much eliminate any need you have for the =RIGHT, =LEFT, =MID, =FIND, and =LEN formulas, or any mixture of those. While useful, these functions can get a bit complicated and need to work in unison in order to produce the same results as =REGEXEXTRACT. A more detailed explanation of these formulas with visuals can be found here.
We'll run the formula on the results produced from running the =QUERY formula. Using =REGEXEXTRACT, we'll select the top cell in the queries column (in this case, C4) and then select everything after it beginning with "@", the start of what we're looking for. Our desired formula will look like =REGEXEXTRACT(C4, "\@.*"). The backslash signifies to escape the following character, and the .* means select everything after. Thus, the formula can be translated as "For cell C4, extract all of the content beginning at the "@".
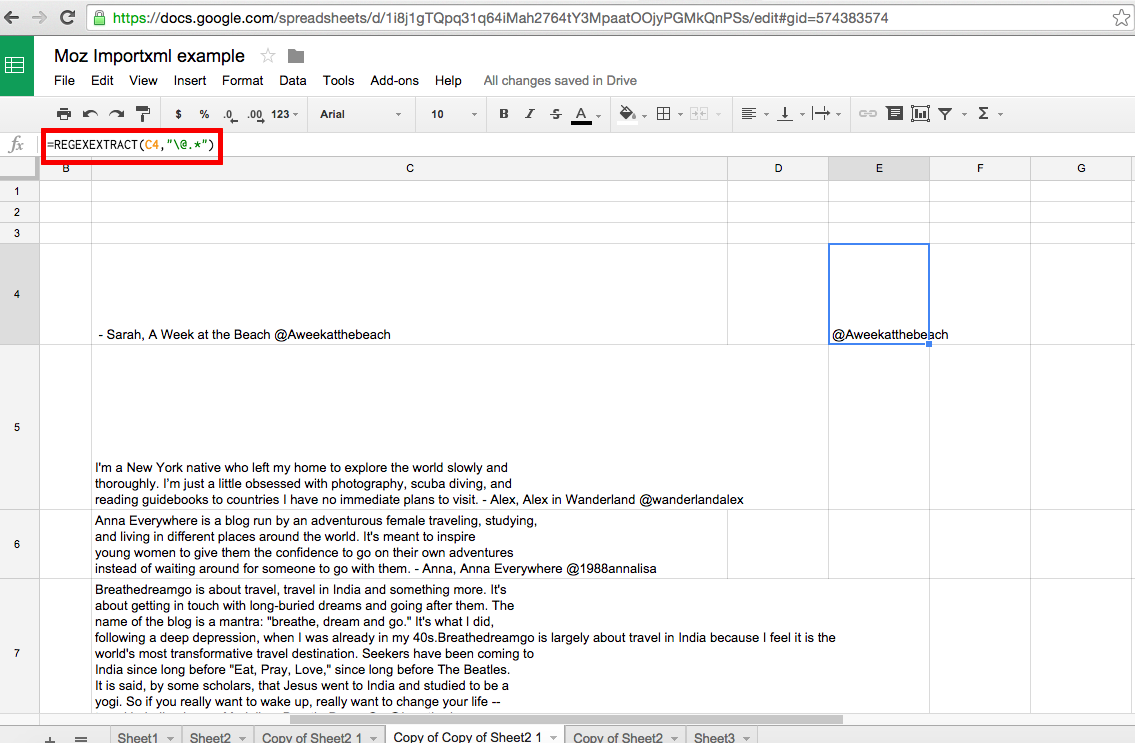
To get all of the other values, all we need to do is click and grab the bottom right corner of cell E4 and drag it down until the end of our array at cell C28. Dragging down the corner of E4 will apply the formula within it to the cells included within the drag. We want to include up to E28 because the corresponding cell C28 is the last cell in the array we are applying the formula to. Doing this will provide the results shown below:
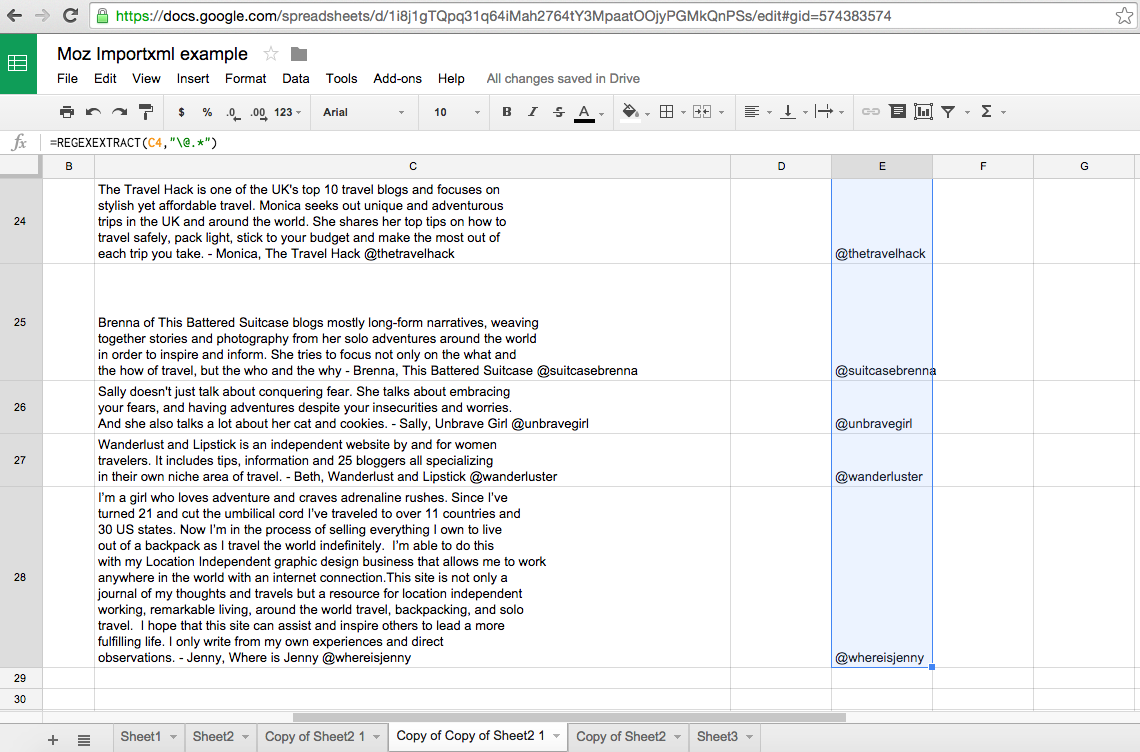
Though a nice and clean output, the data in column E is created by formula and cannot be easily manipulated. We'll need to do copy and paste values within this column to have everything we need and be able to manipulate the data.
If you'd like to play around with the Google Sheet and make your own copy, you can find the original here.
Hopefully this helps provide some direction and insight into how you can easily scrape and clean data from web pages. If you're interested in learning more, here's a list of great resources:
Want more use cases, tips, and things to watch out for when scraping? I interviewed the following experts for their insights into the world of web scraping:
- Dave Sottimano, VP Strategy, Define Media Group, Inc.
- Chad Gingrich, Senior SEO Manager, Seer Interactive
- Dan Butler, Head of SEO, Builtvisible
- Tom Critchlow, tomcritchlow.com
- Ian Lurie, CEO and Founder, Portent, Inc.
- Mike King, Founder, iPullRank
Question 1: Describe a time when automated scraping "saved your life."
"During the time when hreflang was first released, there were a lot of implementation & configuration issues. While isolated testing was very informative, it was the automated scraping of SERPs that helped me realize the impact of certain international configurations and make important decisions for clients." – Dave Sottimano
"We wanted a way to visualize forum data to see what types of questions their clients' audiences were talking about most frequently to be able to create a content strategy out of that data. We scraped Reddit and various forums, grabbing data like post titles, views, number of replies, and even the post content. We were able to aggregate all that data to put together a really interesting look at the most popular questions and visualize keywords within the post title and comments that might be a prime target for content. Another way we use scraping often at Seer is for keyword research. Being able to look at much larger seed keyword sets provides a huge advantage and time savings. Additionally, being able to easily pull search results to inform your keyword research is important and couldn't be done without scraping." – Chad Gingrich
"I'd say scraping saves my life on a regular basis, but one scenario that stands out in particular was when a client requested Schema.org mark-up for each of its 60 hotels in 6 different languages. Straightforward request, or so I thought—turns out they had very limited development resource to implement themselves, and an aged CMS that didn't offer the capabilities of simply downloading a database so that mark up could be appended. Firing up ImportXML in Google Sheets, I could scrape anything (titles, source images, descriptions, addresses, geo-coordinates, etc.), and combined with a series of concatenates was able to compile the data so all that was needed was to upload the code to the corresponding page." – Dan Butler
"I've lost count of the times when ad-hoc scraping has saved my bacon. There were low-stress times when fetching a bunch of pages and pulling their meta descriptions into Excel was useful, but my favorite example in recent times was with a client of mine who was in talks with Facebook to be included in F8. We were crunching data to get into the keynote speech and needed to analyze some social media data for URLs at reasonable scale (a few thousand URLs). It's the kind of data that existed somewhere in the client's system as an SQL query, but we didn't have time to get the dev team to get us the data. It was very liberating to spend 20 minutes fetching and analyzing the data ourselves to get a fast turnaround for Facebook." – Tom Critchlow
"We discovered a client simultaneously pointed all of their home page links at a staging subdomain, and that they'd added a meta robots noindex/nofollow to their home page about one hour after they did it. We saw the crawl result and thought, "Huh, that can't be right." We assumed our crawler was broken. Nope. That's about the best timing we could've hoped for. But it saved the client from a major gaffe that could've cost them tens of thousands of dollars. Another time we had to do a massive content migration from a client that had a static site. The client was actually starting to cut and paste thousands of pages. We scraped them all into a database, parsed them and automated the whole process." – Ian Lurie
"Generally, I hate any task where I have to copy and paste, because any time you're doing that, a computer could be doing it for you. The moment that stands out the most to me is when I first started at Razorfish and they gave me the task of segmenting 3 million links from a Majestic export. I wrote a PHP script that collected 30 data points per link. This was before any of the tools like CognitiveSEO or even LinkDetective existed. Pretty safe to say that saved me from wanting to throw my computer off the top of the building." – Mike King
Question 2: What are your preferred tools/methods for doing it?
"Depends on the scale and the type of job. For quick stuff, it's usually Google docs (ImportXML, or I'll write a custom function), and on scale I really like Scraping Hub. As SEO tasks move closer towards data analysis (science), I think I'll be much more likely to rely on web import modules provided by big data analytics platforms such as RapidMiner or Knime for any scraping." – Dave Sottimano
"Starting out, Outwit is a great tool. It's essentially a browser that lets you build scrapers easily by using the source code. ...I've started using Ruby to have more control and scalability. I chose Ruby because of the front end/backend components, but Python is also a great choice and is definitely a standard for scraping (Google uses it). I think it's inevitable that you learn to code when you're interested in scraping because you're almost always going to need something you can't readily get from simple tools. Other tools I like are the scraper Chrome plugin for quick one page scrapes, Scrapebox, RegExr, & Text2re for building and testing regex. And of course, SEO Tools for Excel." – Chad Gingrich
"I love tools like Screaming Frog and URL Profiler, but find that having the power of a simple spreadsheet behind the approach offers a little more flexibility by saving time being able to manage the output, perform a series of concatenated lookups, and turn it into a dynamic report for ongoing maintenance. Google Sheets also has the ability for you to create custom scripts, so you can connect to multiple APIs or even scrape & convert JSON output. Hey, it's free as well!" – Dan Butler
"Google Docs is by far the most versatile, powerful and fast method for doing this, in my personal experience. I started with ImportXML and cut my teeth using that before graduating to Google Scripts and more powerful, robust, and cron-driven uses. Occasionally, I've used Python to build my own scrapers, but this has so far never really proven to be an effective use of my time—though it has been fun." – Tom Critchlow
"We have our own toolset in-house. It's built on Python and Cython, and has a very powerful regex engine, so we can extract pretty much anything we want. We also write custom tools when we need them to do something really unique, like analyze image types/compression. For really, really big sites—millions of pages—we may use DeepCrawl. But our in-house toolset does the trick 99% of the time and gives us a lot of flexibility." – Ian Lurie
"While I know there a number of WYSIWYG tools for it at this point, I still I prefer writing a script. That way I get exactly what I want and it's in the precise format that I'm looking for." – Mike King
Question 3: What are common pitfalls with web scraping to watch out for?
"Bad data. This ranges from hidden characters and encoding issues to bad HTML, and sometimes you're just being fed crap by some clever system admin. As a general rule, I'd far rather pay for an API than scrape." – Dave Sottimano
"Just because you can scrape something doesn't mean you should, and sometimes too much data just confuses the end goal. I like to outline what I'm going to scrape and why I need it/what I'll do with that data before scraping one piece of data. Use brain power up front, let the scraping automate the rest for you, and you'll come out the other side in a much better place." – Chad Gingrich
"If you're setting up dynamic reports or building your own tools, make sure you have something like Change Detection running so you can be alerted when X% of the target HTML has changed, which could invalidate your Xpath. On the flipside, it's crazy how common parsing private API credentials/authentication is via public HTTP get requests or over XHR—seriously, sites need to start locking this stuff down if they don't want it accessible in the public domain." – Dan Butler
"The most common pitfall with computers is that they only do what you tell them—this sounds obvious, but it's a good reminder that when you get frustrated, you usually only have yourself to blame. Oh—and don't forget to check your recurring tasks every once in a while." – Tom Critchlow
"It's important to slow your crawls down. I'm not even talking about Google scraping. I'm talking about crawling other folks' web sites. I'm continuously amazed at just how poorly optimized most site technology stacks really are. If you start hitting one page a second, you may actually slow or crash a site for a multi-million-dollar business. We once killed a client's site with a one-page-per-second crawl—they were a Fortune 1000 company. It's ridiculous, but it happens more often than you might think. Also, if you don't design your crawler to detect and avoid spider traps, you could end up crawling 250,000 pages of utter duplicate crap. That's a waste of server resources. Once you find an infinitely-expanding URL or other problem, have your crawler move on." – Ian Lurie
"The biggest pitfall I run into these days is that a lot of sites are rendering their content with JavaScript and a standard text-based crawler doesn't always cut it. More often than not, I'm scraping with a headless browser. My favorite abstraction of PhantomJS is NightmareJS because it's quick and easy, so I use that. The other thing is that sometimes people's code is so bad that there's no structure, so you end up grabbing everything and needing to sort through it." – Mike King
Do you have any interesting use-cases or experiences with data scraping? Sound off in the comments!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!








































